文献管理
电子文献管理攻略
之前关于Zotero技巧。
这篇则侧重,如何打造一个半自动化的电子文献资料管理流程。这篇不讲基础安装、云同步等技巧,前面帖子已经讲得够多了。让我们开干吧,超详细,众多技巧汇合,请耐心看。
问题1:如何快速收藏电子书或者论文?
假设在豆瓣看了一本好书,如丹尼特新作【直觉泵】,网址如下:
点击浏览器右上角的Zotero图标,收藏即可:
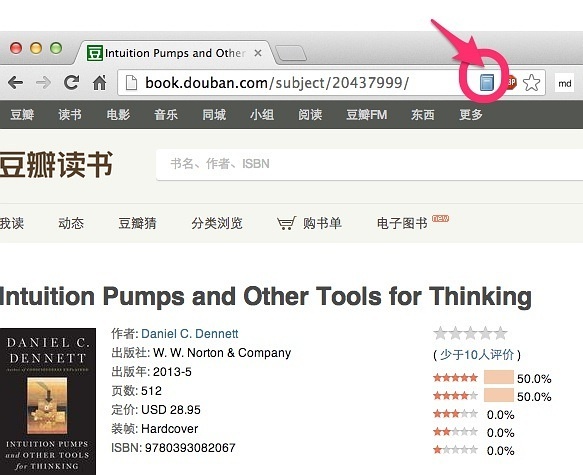 Zotero 1
Zotero 1
好了,打开Zotero,我们看到,该书已经保存在这里了。
 Zotero 2
Zotero 2
同样,对于论文你也可以如此处理,参照老文章,建议多使用Google Scholar
问题2:如何标记文献的重要性?
步骤如下:
1、在丹尼特这本书的条目这里,创建一个【重要文献】类似标签;
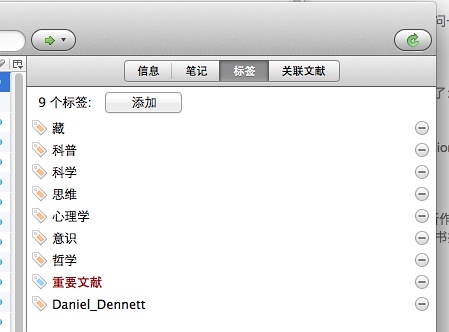 Zotero 3
Zotero 3
2、在界面的左下角,找到【重要文献】该标签,然后右键,对该标签指派颜色:
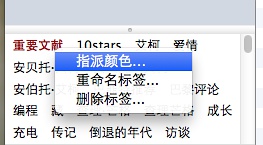 Zotero 4
Zotero 4
比如红色,同时会指派快捷键,如【1】如下图所示:
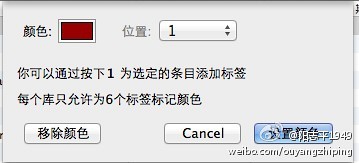 Zotero 5
Zotero 5
3、以上操作只需要执行一次。未来就很爽了,看到好文献,直接键盘按【1】就表示喜欢。最多可分配6个数字。比如,1表示非常重要文献,2表示比较重要文献,诸如此类。
问题3:怎么判断文献重要性?
我们怎么判断文献特别重要呢?有三个简单办法:
- 作者的重要性:比如【H指数】
- 文献的引用次数:比如【Google学术引用次数】
- 文献的学术社交媒体影响力,比如【altmetric分数】
以前的文章与我最近的微博,都谈过最后一个办法【altmetric分数】,这里就不详细说了。只说第一个与第二个办法:H指数与Google学术引用次数。先说第一个:H指数。
H指数是什么?如果人际关系混得不错,在30以上,一般在国内可以拿下学霸地位。超过50,凤毛麟角,属于普通老百姓要珍惜的大牛级别科学家。比如,施一公是60。
比如,丹尼特这位作者的H指数可以在这里查询:Daniel C. Dennett - Google Scholar Citations
我们发现他高达68,那么就表示这位作者非常重要:
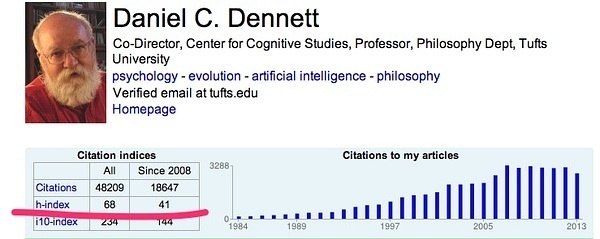 Zotero 6
Zotero 6
我们对丹尼特这本书标记为很重要,那么,选中它,按个【1】就可以了,效果如下图所示:
 Zotero 7
Zotero 7
接下来,我们说说第二个简单办法,【Google学术引用次数】。当然,你可以去Google学术,查看被引次数,然后手动添加。比如,丹尼特这本书被引用9次:
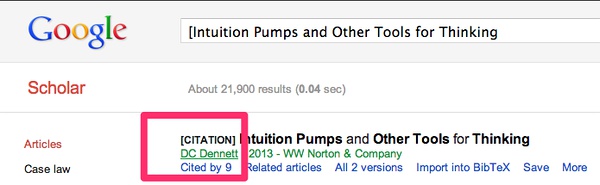 Zotero 8
Zotero 8
不过,懒鬼可不是这思路。我们可以借助插件自动更新【Google学术引用次数】。
因为新读者可能是第一次接触Zotero插件安装,这里多解释几句如何安装插件。
1、打开Zotero的【插件】窗口,位置如下所示:
 Zotero 9
Zotero 9
2、然后下载插件,比如该插件的下载地址是:
3、下载好了,回到Zotero的插件安装界面,如下图所示:
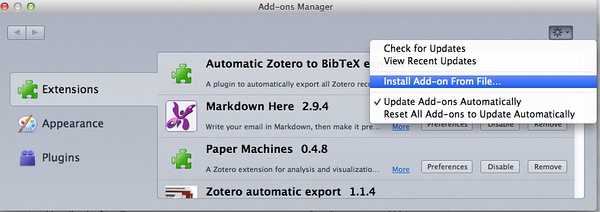 Zotero 10
Zotero 10
安装好了,如有必要,重启Zotero即可。
好的,继续回到丹尼特这本书。我们点击右键,更新一下引用即可。
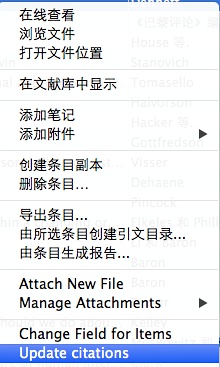 Zotero 11
Zotero 11
问题马上来了,更新完了,我们看条目的【引用次数】那里还是空的啊!老阳,这是怎么回事!
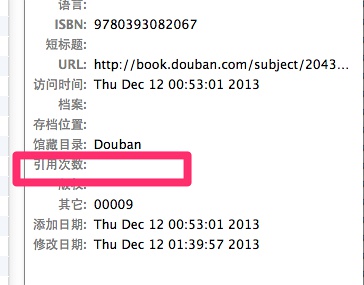 Zotero 12
Zotero 12
别急,这是该插件开发者为了避免将你条目自带的【引用次数】字段与【Google学术引用次数】冲突,所以,他将其保存在【其它】那个字段里面去了。怎么显示它?如下图所示:
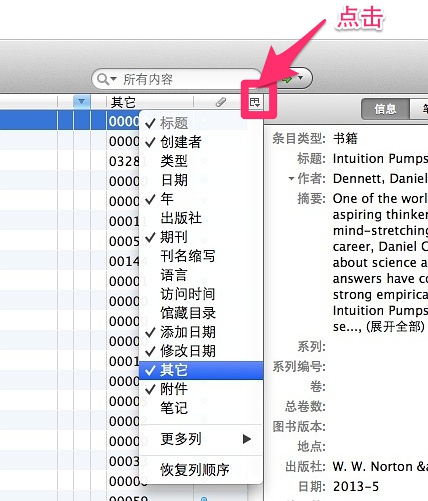 Zotero 13
Zotero 13
勾上它就可以了。我们再重新看一下界面,哇,【Google学术引用次数】真的有了!如下图所示:
 Zotero 14
Zotero 14
丹尼特大神这本书因为才出版没多久,所以才被引9次。而另一位大神2004年出版的Culture, leadership, and organizations,因为属于某个流派开山之作,被引用了3281次。
因为zotero-scholar-citations这个插件是可以批量更新【Google学术引用次数】的。如此一来,我们标记论文、图书重要性,就更容易了。不过需要特别注意的是,Google学术本身为了防止机器人,做了限制,你一次别更新太多文献了,那样,将弹出一个窗口,Google需要你填入验证码,确定你不是机器人,才能继续更新。
问题4:怎样查找英文原版电子书?
说一下怎么查找英文原版书。
1、电子书检索:http://t.cn/zY3Vmkp
这几个网站可检索到70%网上曾出现过的;
2、私有数据库:如果是心理学,推荐APA的psycinfo数据库与MIT的cognet数据库,新书多半可查到;
3、国家图书馆的英文新书非常齐全,多半可复印到,同时可辅以各高校藏书;
4、亚马逊,尤其是kindle直接购买电子书。
问题5:如何保存电子书?
好的,丹尼特这本书,我们假设已经查到了电子书。但是,从网上下载的电子书,命名乱七八糟,不一定符合你的规律,同时,能否自动将下载的电子书导入到Zotero库中?
有,这就是我之前在:Zotero(4):Zotero之Zotfile插件的使用 中介绍过的Zotfile插件。
安装办法仍然同上一个插件一样,我们在它的官网找到插件下载:
http://www.jlegewie.com/zotfile.html
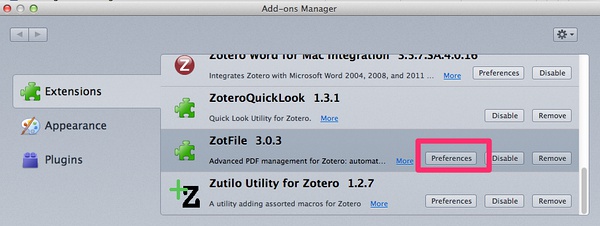
假设,我们平时从网上下载电子资料,都放在【download】目录下面,那么,在插件中心那里,设置Zotfile的常用目录是【download】目录。如下图所示:
 Zotero 15
Zotero 15
继续:
 Zotero 16
Zotero 16
完工!未来我们下载电子书时,就会自动导入。它的原理是这样的:
1、假设在Zotero中,我们的鼠标正选中了丹尼特这本书的条目。
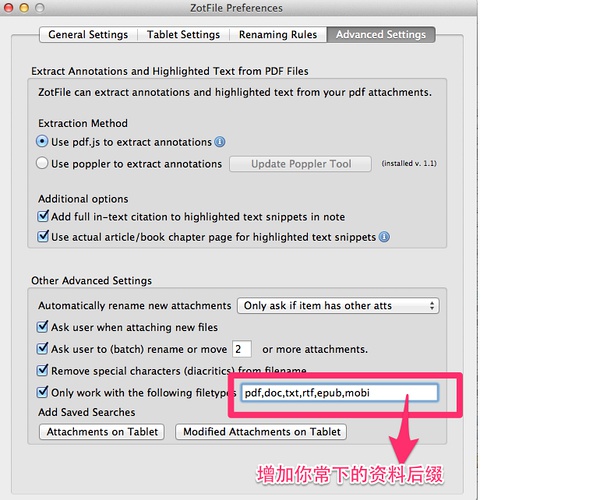
2、此时,我们通过浏览器,下载了这本书的电子版,保存在【download】目录下面。那么,插件Zotfile就会识别出来,并且默认认为这个电子文件是该条目的附件。然后自动导入过来。它默认支持pdf、doc、txt等格式,你也可以设置更多格式,如常用的epub、mobi格式,如下图所示:
 Zotero 17
Zotero 17
3、同时,导入文件成功后,会自动将文件重命名为【作者出版年份文献标题】这种格式。当然,你不喜欢这种文件名格式,也可以在刚才那里自定义其它命名方法。
成功后,如下图所示:
 Zotero 18
Zotero 18
以前那些乱七八糟的PDF怎么处理呢?我们可以将每本电子书拖到对应条目下面。然后批量重命名即可。如下图所示:
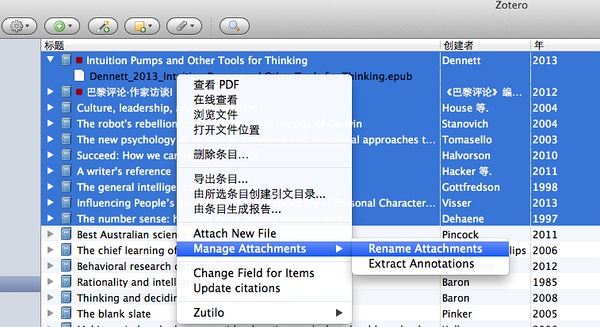 Zotero 19
Zotero 19
问题6:如何写笔记?
好了,收藏狂们一般非常乐意干前面5个步骤,却不太喜欢干这个步骤:读书与写笔记。
Zotero现已支持用Markdown格式写笔记,强!步骤如下,
1)在插件中心,安装Markdown here插件,http://t.cn/8kxA5bG
2)重启后,找到条目,然后新建一笔记,如下图所示:
 Zotero 20
Zotero 20
我们开始用Markdown语法写笔记。这是笔记原文。
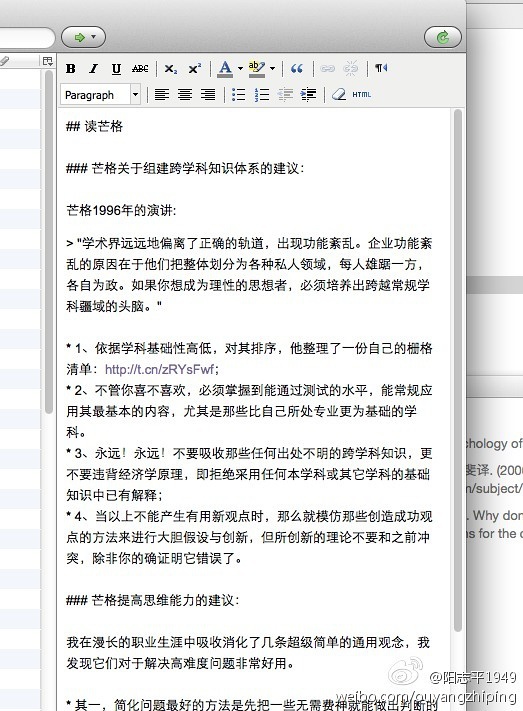 Zotero 21
Zotero 21
按下快捷键:【ctrl+alt+m】,你用Markdown写的笔记就生成为漂亮的文档了!下图是生成效果:
 Zotero 22
Zotero 22
什么?你还在问:Markdown语法是什么?枉我推广这么久。。。
去读这里:Markdown在线写作速成
问题7:Zotero如何配合altmetric分数?
什么是altmetric分数?它可以查出在论文互引网站、推特、科学博客、专业科学媒体上对论文的议论等。 当然,仅限国外科学媒体。
Zotero如何配合使用?我之前的两篇老文章介绍比较详细了,
这里重点讲讲平板上,如iPad上如何配合使用。
科技发展真快,zotero配合altmetric分数,可以按照论文社交媒体影响力,来排序了。这样同行在看的重要论文一目了然了。如下图所示:
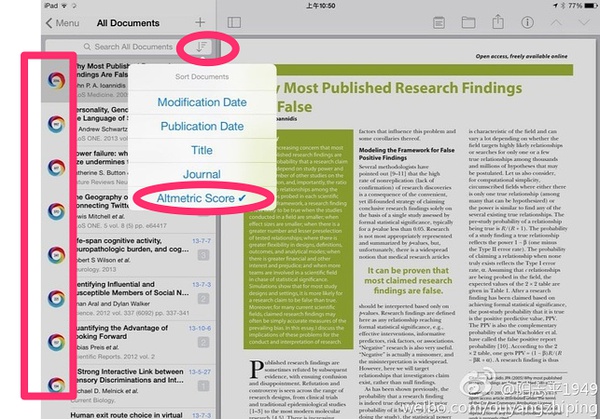 Zotero 23
Zotero 23
将文献按照altmetric分数排序即可。然后社交媒体影响越大的,就越排在前面。扫了一下今年我看的论文,同行热议的,集中在:
- 1、研究方法的讨论,第一篇就是;
- 2、计算社会科学类,如第二篇就是Facebook线索识别人格;
- 3、某个生理区域的突破;
- 4、纵向跟踪研究,如第五篇发现书呆子有利于保护认知老化。
问题8:看资料看晕了,怎么办?
有一种学问,叫做【科学计量学】,研究【科学的科学】,之前也写过很多文章介绍了。比如这篇:
其实,Zotero也可以完成类似任务。这就是我之前介绍过的papermachine插件。下载地址在这里:
How to Use Paper Machines | Paper Machines
对一个类别论文进行【文献可视化】分析,结果如下。先看词云(Word Cloud)的分析结果,如下图所示:
 Zotero 24
Zotero 24
再看看Topic Modeling的分析结果。如下图所示:
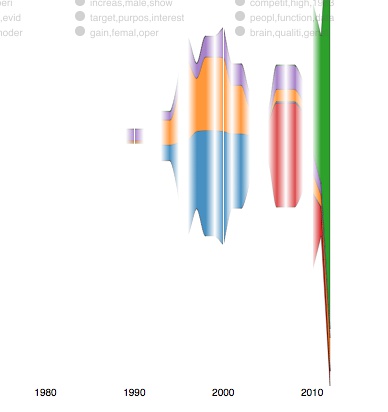 Zotero 25
Zotero 25
前者可以看出该子类论文关键词;后者可看出从1990到2010年,该研究领域随时间的动荡。当然,我选择的示范数据不好,并不能体现出其厉害之处。
一个不算遗憾的小提醒是,papermachine插件目前只支持英文等语种论文分析,另一个问题是,它对版本兼容性要求较高。
问题9:mendeley与 Zotero,哪个更好?
这又是一个读者老问我的问题,谁叫这个世界上,有一种叫做【选择障碍】的病。这么说吧,开源世界的发展速度快于你的想象。 mendeley 被商业公司收购后,很多拥抱开放科学理念的科学家,开始抵制mendeley了,转投Zotero怀抱。如这位:
昨晚帮大家,再次测试mendeley,看一下它最新进展如何,结果还是不得不放弃,安心用我的zotero。它的缺点有什么呢?
- 其一,对于文献量庞大到一定程度的人,程序崩溃太频繁;
- 其二,它的zotero整合功能,还是无法自动导入子文件夹;
- 其三,搜索全方位弱于zotero,在Zotero中,我可以任意定义诸如【豆瓣近7天看的书】,【30天前看的BBS这本刊物的论文】,以备复习使用,而mendeley难以做到;
- 其四,mendeley超过2g空间就收费。Zotero至少10g空间随便用。
- 其五,对于中国用户来说,mendeley还有个致命缺点,无法导入豆瓣读书记录与github的程序库;无法将笔记与论文区分开。这样,只能将其当做文献管理软件而非知识管理软件用。
贵阳小杨哥(http://blog.yesmryang.net/tags/Zotero/),也是忠实的开源软件Zotero推广者,在我的微博评论下,补充道:,也是忠实的开源软件Zotero推广者,在我的微博评论下,补充道:)
Zotero早就可以把「附件」和「题录」分开放置了!附件放Dropbox/skydrive/百度盘什么的,20G不是问题!
小结
开源程序的发展速度往往超出人们想象。目前Zotero引领的开源引文格式项目——CSL,已经突破六千多期刊。以致商业科技出版公司的人不敢相信。每过一些日子,你又会发现一些好用的小技巧。隔一段时间,对天天用的软件,更新使用模式,是个好习惯。同时,开源程序总具备一种质朴的美。Zotero将电子书或PDF、笔记、引用文献三者放在一起,从下载电子书或PDF,到阅读、做标注、写笔记,再到引用,一条龙服务,非常方便。有特别不满意的地方,源代码公开了,自己修改就好了。
我们还可以自定义这些zotero搜索类别:【2013年看过的书】、【2013年看过的论文】与【2013年写过的读书笔记】、【2013年阅读的最重要的论文】或者【2013年同行评价最高的论文】。年底这么整理一下,温故而知新,也很有成就感:D